PDF RAG Application
A full-stack application that enables AI-powered conversations with PDF documents
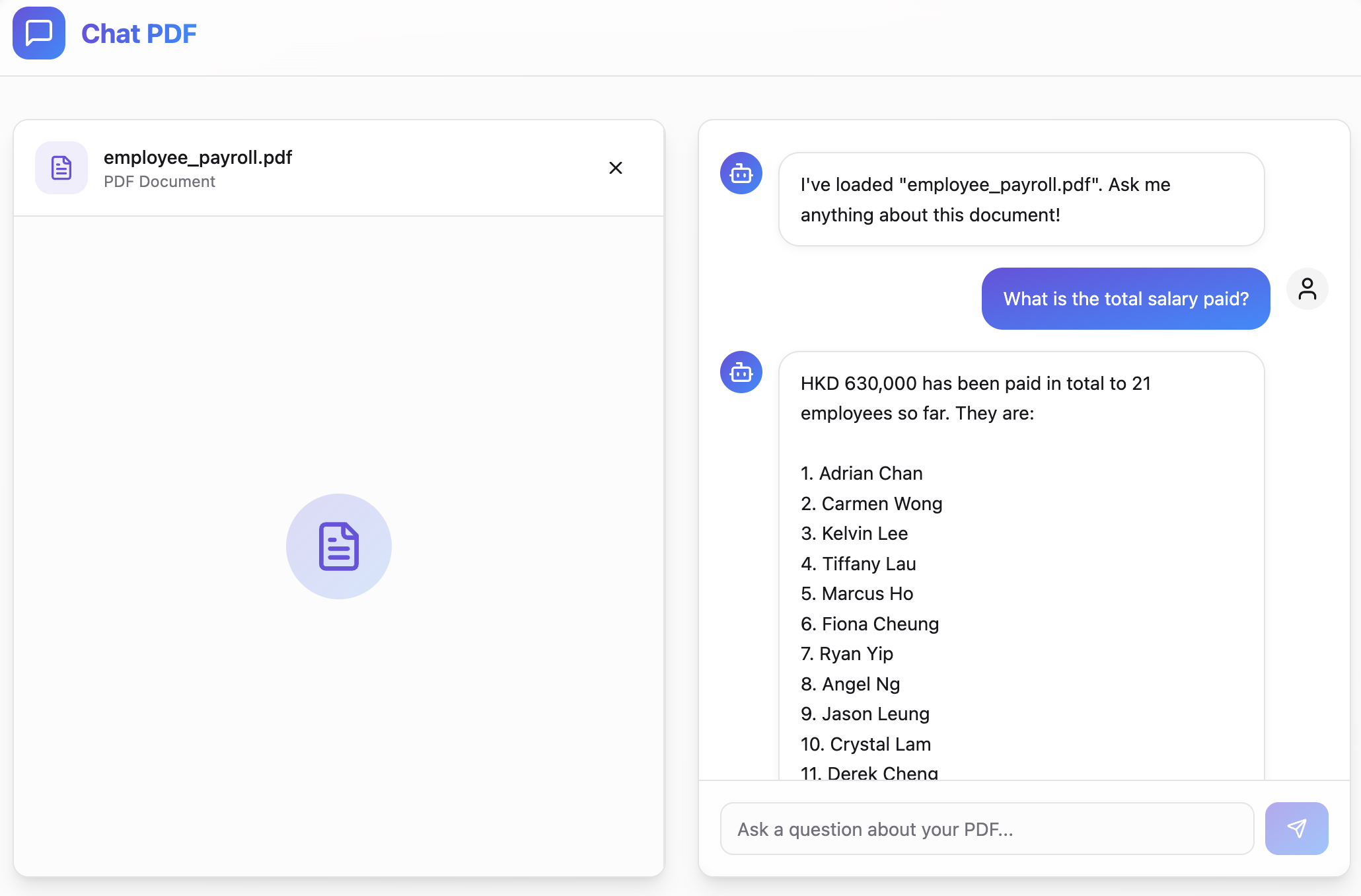
Project Overview
This project leverages Azure OpenAI's GPT-4 and embedding models to provide intelligent, context-aware responses based on uploaded PDF content. Users can upload PDF documents, ask questions about them, and receive accurate answers based on the document's content.
The application uses advanced natural language processing techniques to understand both the user's queries and the document content, creating a seamless conversational experience that feels like chatting with an expert who has read and memorized the entire document.
Technical Architecture
The PDF RAG application is built on a modern, scalable architecture designed for performance and reliability. The system processes documents in the background, extracts meaningful content, and creates vector embeddings for semantic search capabilities.
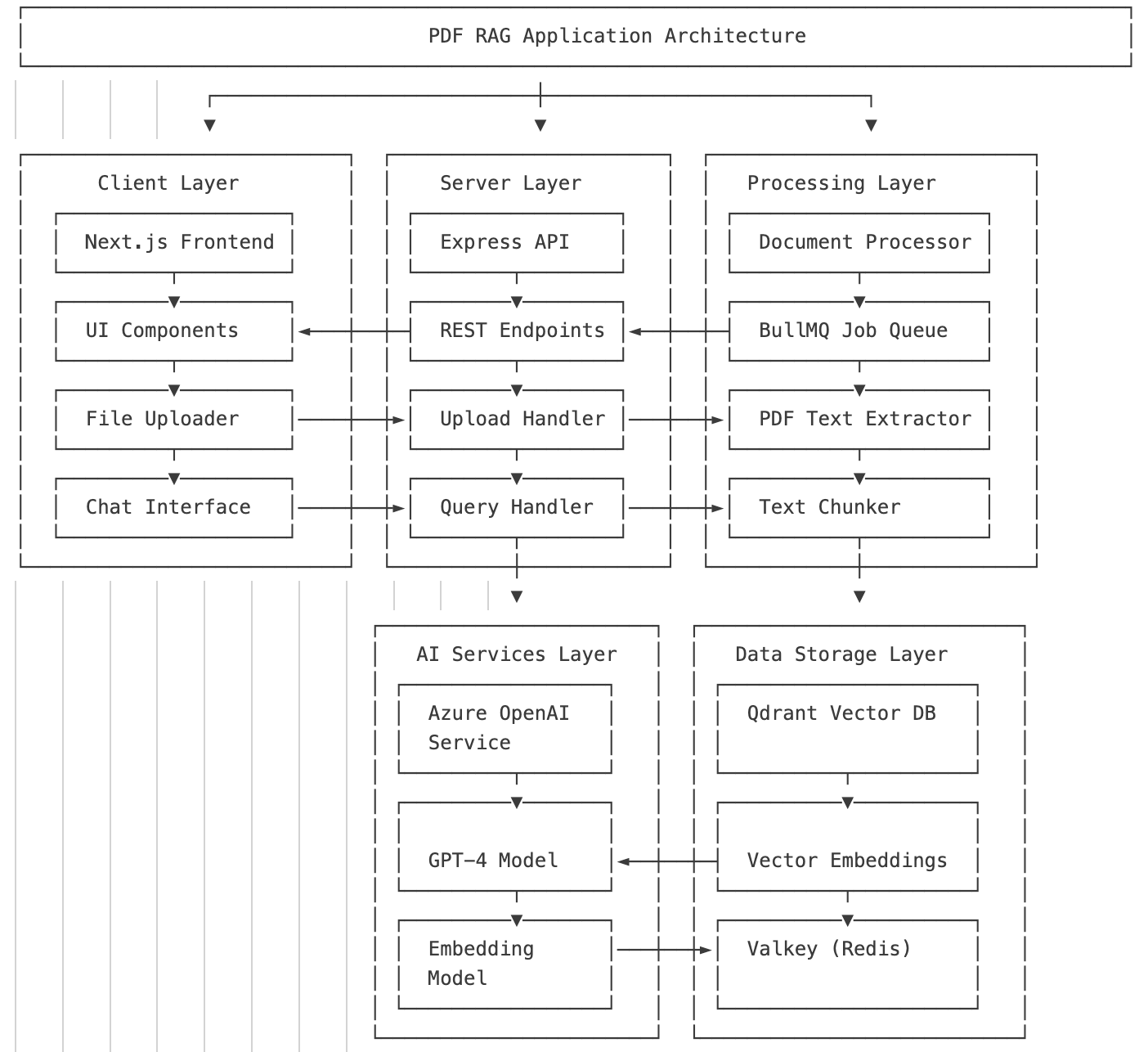
Frontend Stack
- Next.js - React framework for server-side rendering
- React - UI component library for interactive interfaces
- TypeScript - Type-safe JavaScript for robust development
- Tailwind CSS - Utility-first CSS framework
Backend Stack
- Node.js - JavaScript runtime for server-side operations
- Express - Web framework for handling API requests
- BullMQ - Job queue for background processing
- Valkey - Redis-compatible in-memory data store
Data Process Flow
The PDF RAG application follows a sophisticated data processing flow that enables intelligent document understanding and question answering. Here's how data moves through the system:
Document Processing
- User uploads PDF document through the File Uploader component
- Upload Handler processes the file and creates a job in the BullMQ queue
- Document Processor extracts text from PDF and splits it into chunks
- Text chunks are converted to vector embeddings using Azure OpenAI embedding model
- Vector embeddings are stored in Qdrant Vector Database
Query Processing
- User asks questions through the Chat Interface
- Query Handler processes the question and creates a vector embedding
- Similar chunks are retrieved from Qdrant using vector similarity search
- Retrieved chunks are sent to GPT-4 as context along with the user's question
- GPT-4 generates a response which is returned to the user through the Chat Interface
AI Integration
The application integrates with Azure OpenAI services to provide powerful natural language understanding and generation capabilities. This integration enables the system to:
Document Understanding
Using Azure OpenAI's embedding models, the application creates vector representations of document content that capture semantic meaning, enabling intelligent retrieval of relevant information.
text-embedding-3-small: Creates 1536-dimensional vectors that capture semantic relationships between text chunks
Contextual Responses
The GPT-4 model generates natural, human-like responses that incorporate specific information from the document, providing accurate answers to user queries.
GPT-4: Advanced language model that synthesizes information from retrieved document chunks to generate coherent answers
Azure OpenAI Integration
Enterprise-grade security with Azure AD integration and private endpoints
Meets regulatory requirements with data residency options
Handles high-volume processing with optimized throughput
Vector Database & Semantic Search
At the core of the PDF RAG application is Qdrant, a high-performance vector database optimized for similarity search. When a document is uploaded, it's processed into chunks, and each chunk is converted into a vector embedding that captures its semantic meaning.
Vector Search Process
When a user asks a question, the application:
- Converts the question into a vector embedding
- Searches the vector database for similar content chunks
- Retrieves the most relevant document sections
- Uses these sections as context for generating an accurate response
Benefits
- Precise answers to complex questions
- Fast retrieval of relevant information
- Efficient processing without analyzing entire documents
- Semantic understanding beyond keyword matching
- Scalable to handle large document collections
This approach enables the system to provide precise answers even for complex questions about lengthy documents, without requiring the AI to process the entire document for each query.
Containerization & Deployment
The application is containerized using Docker and orchestrated with Docker Compose, making it easy to deploy in various environments. This containerization approach ensures consistency across development, testing, and production environments.
Container Architecture
Application Containers
Next.js frontend with React components for file upload and chat interface
Node.js backend with Express API endpoints for document processing and query handling
Data Service Containers
Redis-compatible in-memory data store for job queue management with BullMQ
Vector database for storing and retrieving document embeddings with similarity search
Deployment Benefits
Each container can be scaled independently based on load requirements
Consistent environment across development, testing, and production
Services run independently with their own dependencies and resources